Appearance
AI/ML 基础
理解大语言模型背后的核心原理
学习目标
- 理解机器学习三大范式
- 掌握 Transformer 架构核心机制
- 了解 LLM 的训练与推理过程
1. 机器学习基础
机器学习是让计算机从数据中自动学习规律的技术,无需显式编程。根据学习方式的不同,分为三大范式。
1.1 监督学习
监督学习使用带标签的数据进行训练,模型学习输入到输出的映射关系。
分类与回归:
分类:输入 → 离散标签 (如:邮件 → 垃圾/正常)
回归:输入 → 连续数值 (如:房屋特征 → 价格)损失函数衡量预测值与真实值的差距:
python
# 均方误差(回归)
MSE = (1/n) * Σ(y_pred - y_true)²
# 交叉熵(分类)
CrossEntropy = -Σ y_true * log(y_pred)梯度下降是最核心的优化算法——沿着损失函数梯度的反方向更新参数:
python
# 梯度下降伪代码
for epoch in range(num_epochs):
loss = compute_loss(model(X), y)
gradients = compute_gradients(loss, parameters)
parameters = parameters - learning_rate * gradients1.2 无监督学习
无监督学习处理无标签数据,发现数据中的隐藏结构。
| 任务 | 目标 | 典型算法 |
|---|---|---|
| 聚类 | 将相似数据分组 | K-Means, DBSCAN |
| 降维 | 压缩数据维度 | PCA, t-SNE, UMAP |
| 异常检测 | 识别异常样本 | Isolation Forest |
💡 Embedding(嵌入)本质上就是一种降维——将高维离散数据映射到低维连续向量空间,这是 LLM 和 RAG 的基础。
1.3 强化学习
强化学习通过 Agent 与环境交互,根据奖励信号学习最优策略。
关键概念:
- 策略(Policy):Agent 在给定状态下选择动作的规则
- 奖励(Reward):环境对动作的反馈信号
- RLHF(人类反馈强化学习):用人类偏好作为奖励信号来对齐 LLM,是 ChatGPT 成功的关键技术之一
2. 神经网络基础
2.1 前馈神经网络
神经网络由多层神经元组成,每个神经元执行:加权求和 → 激活函数 → 输出。
激活函数引入非线性,使网络能拟合复杂模式:
python
# ReLU:最常用,计算高效
ReLU(x) = max(0, x)
# GELU:Transformer 中广泛使用
GELU(x) = x * Φ(x) # Φ 为标准正态分布的累积分布函数
# Softmax:将输出转为概率分布(用于分类/Token 预测)
Softmax(x_i) = exp(x_i) / Σ exp(x_j)2.2 反向传播
反向传播是训练神经网络的核心算法:从输出层向输入层逐层计算梯度,然后更新权重。
常见优化器:
| 优化器 | 特点 |
|---|---|
| SGD | 基础,需手动调学习率 |
| Adam | 自适应学习率,最常用 |
| AdamW | Adam + 权重衰减,Transformer 训练标配 |
2.3 常见架构
| 架构 | 特点 | 应用 |
|---|---|---|
| CNN | 卷积核提取局部特征 | 图像识别、视觉模型 |
| RNN/LSTM | 循环结构处理序列 | 早期 NLP(已被 Transformer 取代) |
| Seq2Seq | 编码器-解码器结构 | 机器翻译(Transformer 的前身) |
💡 Transformer 的出现彻底改变了 NLP 领域——它用 Attention 机制替代了 RNN 的循环结构,实现了并行计算,成为现代 LLM 的基石。
3. Transformer 架构
2017 年,Google 团队发表了划时代的论文 "Attention Is All You Need",提出了 Transformer 架构。它完全抛弃了 RNN 的循环结构和 CNN 的卷积操作,仅依靠注意力机制(Attention)来建模序列中的全局依赖关系,实现了高度并行化的训练,奠定了现代 LLM 的基础。
3.1 整体架构
Transformer 采用经典的 编码器-解码器(Encoder-Decoder) 结构。编码器将输入符号序列 (x₁, ..., xₙ) 映射为连续表示 z = (z₁, ..., zₙ);解码器根据 z 逐个生成输出序列 (y₁, ..., yₘ),每一步都是自回归的——将之前已生成的符号作为额外输入。
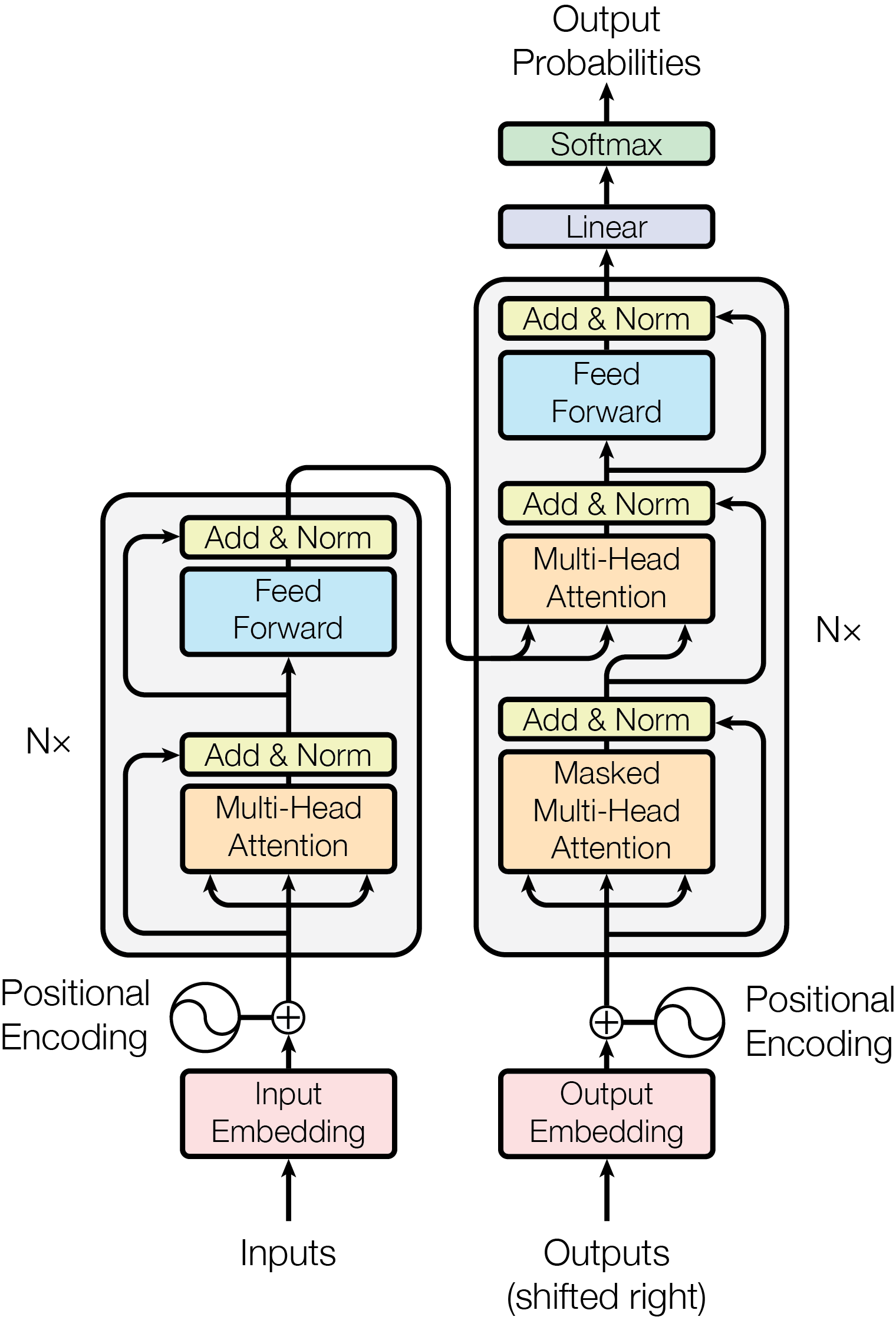
上图左半部分为编码器,右半部分为解码器。核心组件包括:
| 组件 | 作用 |
|---|---|
| Input/Output Embedding | 将 Token 转换为 d_model 维向量 |
| Positional Encoding | 注入位置信息(Transformer 无循环结构) |
| Multi-Head Attention | 多头注意力,捕获不同子空间的依赖关系 |
| Masked Multi-Head Attention | 带掩码的注意力,防止解码器"偷看"未来位置 |
| Feed Forward | 逐位置的前馈网络,提供非线性变换 |
| Add & Norm | 残差连接 + Layer Normalization,稳定训练 |
编码器由 N=6 个相同的层堆叠而成,每层包含两个子层:多头自注意力 + 前馈网络,每个子层都有残差连接和 Layer Normalization。
解码器同样由 N=6 个相同的层堆叠,但每层多了一个子层:对编码器输出做交叉注意力(Cross-Attention),使解码器能关注输入序列的所有位置。解码器的自注意力层使用掩码(Mask),确保位置 i 的预测只能依赖位置 i 之前的已知输出。
3.2 Scaled Dot-Product Attention
注意力机制的本质是:给定一个查询(Query),从一组键值对(Key-Value)中检索相关信息。
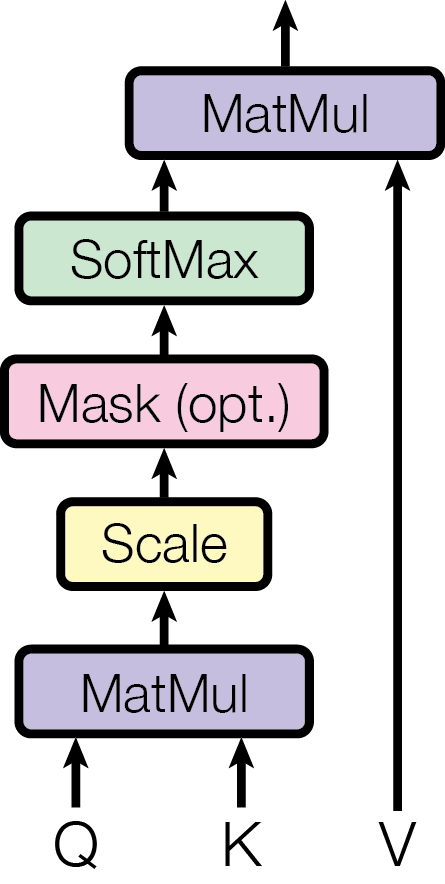
计算公式:
Attention(Q, K, V) = Softmax(Q · Kᵀ / √d_k) · V逐步拆解:
- Q · Kᵀ:计算查询与每个键的点积,得到相关性分数
- / √d_k:缩放因子。当 d_k 较大时,点积值会很大,导致 Softmax 梯度极小,除以 √d_k 可以缓解这个问题
- Softmax:将分数归一化为注意力权重(概率分布)
- · V:按权重对值进行加权求和,得到输出
论文解释了为什么需要缩放:假设 Q 和 K 的分量是均值为 0、方差为 1 的独立随机变量,则它们的点积均值为 0,方差为 d_k。d_k 越大,点积值越大,Softmax 会被推入梯度极小的区域。
3.3 Multi-Head Attention
与其用单个注意力函数处理 d_model 维的 Q/K/V,不如将它们线性投影到多个低维子空间,分别做注意力计算,再拼接结果:
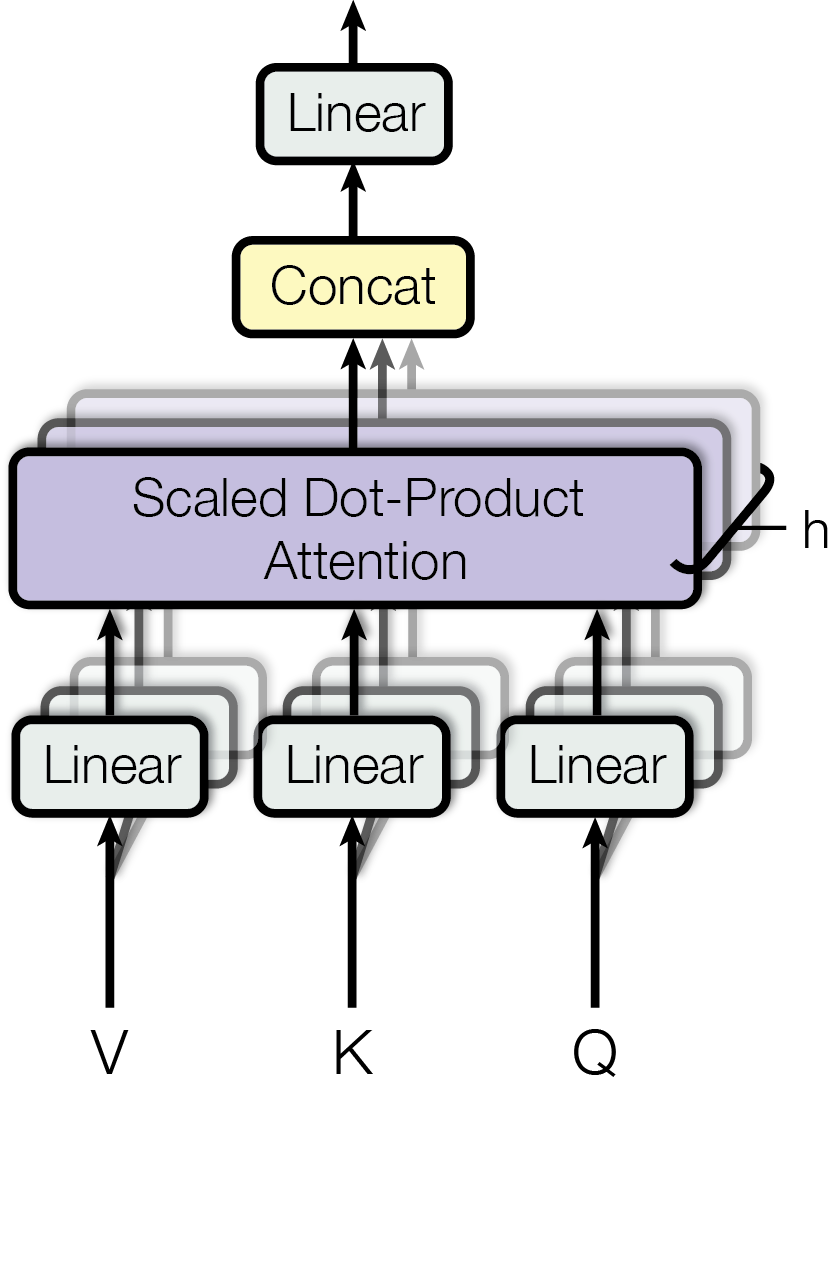
计算公式:
MultiHead(Q, K, V) = Concat(head₁, ..., headₕ) · Wᴼ
其中 headᵢ = Attention(Q·WᵢQ, K·WᵢK, V·WᵢV)论文中使用 h=8 个注意力头,每个头的维度 d_k = d_v = d_model / h = 64。由于每个头的维度降低了,总计算量与单头全维度注意力相当。
多头的意义:不同的注意力头可以从不同的表示子空间捕获不同类型的关系——有的头关注语法结构,有的头关注语义关联,有的头捕获长距离依赖。
注意力在模型中的三种应用:
| 应用场景 | Q 来源 | K/V 来源 | 说明 |
|---|---|---|---|
| 编码器自注意力 | 编码器上一层 | 编码器上一层 | 每个位置关注输入序列的所有位置 |
| 解码器自注意力(带掩码) | 解码器上一层 | 解码器上一层 | 每个位置只能关注当前及之前的位置 |
| 编码器-解码器交叉注意力 | 解码器上一层 | 编码器输出 | 解码器关注输入序列的所有位置 |
3.4 Position-wise Feed-Forward Network
每层中除了注意力子层,还有一个逐位置的前馈网络,对每个位置独立且相同地应用:
FFN(x) = max(0, x·W₁ + b₁)·W₂ + b₂这是两个线性变换中间夹一个 ReLU 激活。论文中输入输出维度 d_model = 512,内层维度 d_ff = 2048(4 倍扩展)。
可以将 FFN 理解为"知识存储层"——注意力层负责信息路由(哪些 Token 相关),FFN 负责信息处理(对内容做非线性变换)。
3.5 位置编码(Positional Encoding)
Transformer 没有循环和卷积结构,无法感知 Token 的顺序。为此,论文在输入 Embedding 上叠加了位置编码:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))其中 pos 是位置,i 是维度索引。每个维度对应一个不同频率的正弦波,波长从 2π 到 10000·2π 呈几何级数递增。
为什么选择正弦编码:对于任意固定偏移 k,PE(pos+k) 可以表示为 PE(pos) 的线性函数,这使模型能够轻松学习相对位置关系。论文也实验了可学习的位置编码,效果几乎相同,但正弦编码可能更容易泛化到训练时未见过的序列长度。
现代位置编码的演进:
| 编码方式 | 原理 | 使用模型 |
|---|---|---|
| 正弦编码 | 不同频率的正弦/余弦函数 | 原始 Transformer |
| RoPE | 旋转位置编码,将位置信息融入 Q/K 的旋转矩阵 | LLaMA, Qwen, DeepSeek |
| ALiBi | 在注意力分数上加线性偏置 | BLOOM, MPT |
💡 RoPE 是目前最主流的位置编码方案,支持通过 NTK-aware 插值等技术扩展上下文长度。
3.6 为什么 Self-Attention 优于 RNN 和 CNN
论文从三个维度对比了 Self-Attention、RNN 和 CNN:
| 指标 | Self-Attention | RNN | CNN |
|---|---|---|---|
| 每层计算复杂度 | O(n²·d) | O(n·d²) | O(k·n·d²) |
| 最少顺序操作数 | O(1) | O(n) | O(1) |
| 最大路径长度 | O(1) | O(n) | O(log_k(n)) |
关键优势:
- 并行性:Self-Attention 所有位置可以同时计算,而 RNN 必须逐步顺序处理(O(n) 顺序操作)
- 长距离依赖:任意两个位置之间的路径长度为 O(1),RNN 需要 O(n) 步才能传递信息,CNN 需要 O(log_k(n)) 层
- 可解释性:注意力权重可以直观展示模型在关注什么,不同的注意力头会学到不同的语言结构
当序列长度 n 小于表示维度 d 时(这在实际 NLP 任务中很常见),Self-Attention 的计算量也优于 RNN。
3.7 训练细节
论文中的关键训练配置:
| 配置项 | Base 模型 | Big 模型 |
|---|---|---|
| 层数 N | 6 | 6 |
| d_model | 512 | 1024 |
| d_ff | 2048 | 4096 |
| 注意力头数 h | 8 | 16 |
| 参数量 | 65M | 213M |
| 训练时间 | 12 小时 (8×P100) | 3.5 天 (8×P100) |
优化器:Adam(β₁=0.9, β₂=0.98),配合 Warmup 学习率调度——前 4000 步线性增长,之后按步数的平方根倒数衰减。
正则化:
- Residual Dropout(P_drop=0.1):在每个子层输出上应用 Dropout,然后再做残差连接和归一化
- Label Smoothing(ε_ls=0.1):牺牲一点困惑度,但提升准确率和 BLEU 分数
3.8 Transformer 的三种衍生架构
原始 Transformer 是 Encoder-Decoder 结构,后续衍生出三种主要架构:
| 架构 | 代表模型 | 适用任务 |
|---|---|---|
| Encoder-only | BERT, RoBERTa | 文本分类、NER、Embedding |
| Decoder-only | GPT-4o, Claude, LLaMA, Qwen, DeepSeek | 文本生成、对话、代码 |
| Encoder-Decoder | T5, BART | 翻译、摘要 |
💡 当前主流 LLM 几乎都采用 Decoder-only 架构,因为它在自回归生成任务上表现最好,且更容易通过 Scaling 提升性能。
3.9 现代 Transformer 的关键改进
相比原始论文,现代 LLM 在 Transformer 基础上做了诸多改进:
Pre-Norm vs Post-Norm:
原始论文 (Post-Norm): LayerNorm(x + SubLayer(x))
现代模型 (Pre-Norm): x + SubLayer(LayerNorm(x))Pre-Norm 将归一化放在子层之前,训练更稳定。RMSNorm 是更高效的变体,被 LLaMA、DeepSeek 等模型采用。
KV Cache:
推理时缓存已计算的 Key 和 Value,避免重复计算:
无 KV Cache:每生成一个 Token,重新计算所有 Token 的 K/V
有 KV Cache:只计算新 Token 的 Q,复用之前的 K/V
效果:推理速度大幅提升,但显存占用增加其他改进:
| 改进 | 说明 | 采用模型 |
|---|---|---|
| GQA(分组查询注意力) | 多个 Q 头共享一组 K/V,减少 KV Cache 显存 | LLaMA 2/3, Qwen2 |
| SwiGLU 激活 | 替代 ReLU,效果更好 | LLaMA, PaLM, DeepSeek |
| Flash Attention | IO 感知的精确注意力算法,大幅加速训练和推理 | 几乎所有现代模型 |
| MoE(混合专家) | 稀疏激活,用更少计算量达到更大模型容量 | Mixtral, DeepSeek-V3 |
4. 大语言模型(LLM)
4.1 预训练
LLM 的预训练目标是自回归语言建模——给定前面的 Token,预测下一个 Token:
P(token_n | token_1, token_2, ..., token_{n-1})训练数据:
- 规模:数万亿 Token(Common Crawl、Wikipedia、书籍、代码等)
- 质量:数据清洗和去重至关重要
- 多语言:中英文混合训练提升跨语言能力
Scaling Laws(Chinchilla 定律):
模型性能 ≈ f(模型参数量 N, 训练数据量 D, 计算量 C)
经验法则:训练 Token 数 ≈ 20 × 模型参数量
例:7B 模型 → 约需 140B Token 训练数据💡 Scaling Laws 表明:在固定计算预算下,模型大小和数据量需要均衡增长,而非一味增大模型。
4.2 指令微调(Instruction Tuning)
预训练后的模型只会"续写",需要通过指令微调让它学会"遵循指令"。
SFT(Supervised Fine-Tuning):
json
{
"instruction": "将以下英文翻译成中文",
"input": "Large Language Models are transforming AI applications.",
"output": "大语言模型正在变革 AI 应用。"
}指令数据集构建:
- 人工标注:质量高但成本大
- Self-Instruct:用强模型生成指令数据
- Evol-Instruct:逐步增加指令复杂度(WizardLM 方法)
4.3 RLHF / DPO
让模型输出更符合人类偏好。
RLHF(人类反馈强化学习):
1. 收集人类偏好数据:对同一 Prompt 的多个回答排序
2. 训练奖励模型(Reward Model):学习人类偏好
3. PPO 优化:用奖励模型的分数作为强化学习的奖励信号DPO(直接偏好优化):
跳过奖励模型,直接从偏好数据优化策略:
Loss = -log σ(β · (log π(y_w|x)/π_ref(y_w|x) - log π(y_l|x)/π_ref(y_l|x)))
y_w = 人类偏好的回答(winner)
y_l = 人类不偏好的回答(loser)💡 DPO 比 RLHF 更简单稳定,已成为主流对齐方法。DeepSeek、Qwen 等模型均采用 DPO 或其变体。
4.4 Tokenization
LLM 不直接处理文本,而是先将文本切分为 Token(子词单元)。
BPE(Byte Pair Encoding):
原始文本: "lower"
字符级: ['l', 'o', 'w', 'e', 'r']
BPE 合并: ['low', 'er'] (高频字符对逐步合并)常见 Tokenizer:
| Tokenizer | 使用模型 | 词表大小 |
|---|---|---|
| tiktoken (BPE) | GPT-4o | ~200K |
| SentencePiece | LLaMA, Qwen | 32K~152K |
Token 与成本的关系:
python
# 粗略估算
1 个英文单词 ≈ 1-2 个 Token
1 个中文字 ≈ 1-2 个 Token
# API 计费示例(以 GPT-4o 为例)
输入: $2.50 / 1M Token
输出: $10.00 / 1M Token
# 一次对话成本估算
输入 1000 Token + 输出 500 Token ≈ $0.0025 + $0.005 = $0.00755. 推理过程
5.1 自回归生成
LLM 逐个 Token 生成文本,每次将已生成的序列作为输入预测下一个 Token:
KV Cache 加速:
Step 1: 计算 "今天天气" 的 K/V → 缓存
Step 2: 只计算 "真" 的 Q,复用缓存的 K/V → 追加缓存
Step 3: 只计算 "不" 的 Q,复用缓存的 K/V → 追加缓存
...5.2 采样策略
模型输出的是每个 Token 的概率分布,采样策略决定如何从中选择:
| 策略 | 说明 | 效果 |
|---|---|---|
| Temperature | 控制概率分布的"锐度" | 低值(0.1)→确定性高;高值(1.5)→更随机 |
| Top-p (Nucleus) | 只从累积概率达到 p 的 Token 中采样 | p=0.9 → 排除低概率长尾 |
| Top-k | 只从概率最高的 k 个 Token 中采样 | k=50 → 限制候选范围 |
| Greedy | 始终选概率最高的 Token | 确定性输出,但可能重复 |
| Beam Search | 维护多个候选序列,选全局最优 | 翻译等任务常用 |
python
# 实际使用建议
# 创意写作
{"temperature": 0.9, "top_p": 0.95}
# 代码生成
{"temperature": 0.2, "top_p": 0.9}
# 数据提取/分类
{"temperature": 0.0} # 等价于 Greedy5.3 上下文窗口
上下文窗口是模型单次能处理的最大 Token 数,包括输入和输出。
| 模型 | 上下文长度 |
|---|---|
| GPT-4o | 128K |
| Claude 3.5 Sonnet | 200K |
| Gemini 1.5 Pro | 2M |
| DeepSeek-V3 | 128K |
| Qwen2.5 | 128K |
长文本处理策略:
- 滑动窗口:将长文本分段处理,保留重叠部分
- RAG:检索相关片段而非塞入全部内容(详见 RAG 章节)
- 摘要压缩:先对长文本生成摘要,再基于摘要回答
- 长上下文模型:直接使用支持超长上下文的模型
💡 虽然模型支持的上下文越来越长,但"大海捞针"测试表明,信息在上下文中间位置时检索效果会下降。合理使用 RAG 仍然是处理大量文档的最佳实践。
练习
- 手绘 Transformer 架构图并标注各组件(Self-Attention、FFN、LayerNorm、残差连接)
- 使用 OpenAI API 对比不同 Temperature 值(0.0 / 0.7 / 1.5)对生成结果的影响
- 使用
tiktoken库计算一段中英文混合文本的 Token 数量,并估算 API 调用成本
python
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4o")
text = "大语言模型 (LLM) 正在改变软件开发的方式。"
tokens = enc.encode(text)
print(f"Token 数量: {len(tokens)}")
print(f"Token 列表: {tokens}")
print(f"解码验证: {[enc.decode([t]) for t in tokens]}")延伸阅读
- Attention Is All You Need — Transformer 原始论文
- The Illustrated Transformer — 可视化讲解 Transformer
- nanoGPT — Karpathy 的极简 GPT 实现
- Scaling Laws for Neural Language Models — Scaling Laws 论文
- Training Compute-Optimal Large Language Models — Chinchilla 论文
- Direct Preference Optimization — DPO 论文